TA的每日心情 | 开心
2019-8-21 08:44 |
|---|
签到天数: 163 天 [LV.7]常住居民III
状元
 
- 积分
- 14980
|
- '''
- Based on xmllarge.py
- '''
- # from pyquery import PyQuery as pq
- from pathlib import Path
- def xml_iter(file, tag):
- '''
- Process huge xml files
- <tag> </tag> need to be in separate lines
- # TODO: in the middle of lines
- :file: file path
- :tag: element to retrieve
- '''
- tagb1 = '<' + tag + '>'
- tagb1 = tagb1.encode()
- tagb2 = '<' + tag + ' '
- tagb2 = tagb2.encode()
- tagb3 = '</' + tag + '>'
- tagb3 = tagb3.encode()
- with open(file, 'rb') as inputfile:
- append = False
- for line in inputfile:
- #~ if b'<tu>' in line or b'<tu ' in line:
- if tagb1 in line:
- inputbuffer = line[line.index(tagb1):]
- append = True
- elif tagb2 in line:
- inputbuffer = line[line.index(tagb2):]
- append = True
- #~ elif b'</tu>' in line:
- elif tagb3 in line:
- inputbuffer += line[:line.index(tagb3) + len(tagb3)]
- append = False
- yield inputbuffer
- #~ docitem = process_buffer(inputbuffer, id_num)
- #~ print(id_num)
- #~ id_num += 1
- inputbuffer = b''
- elif append:
- inputbuffer += line
这么多人找这东西?我过一阵打包发个小工具。
上面的python3函数用法
resu = ''
for elm in xml_iter(filename, 'tu'):
resu += elm
内存足迹极小……不管文件多大。 |
|









 发表于 2013-11-24 17:50:00
发表于 2013-11-24 17:50:00


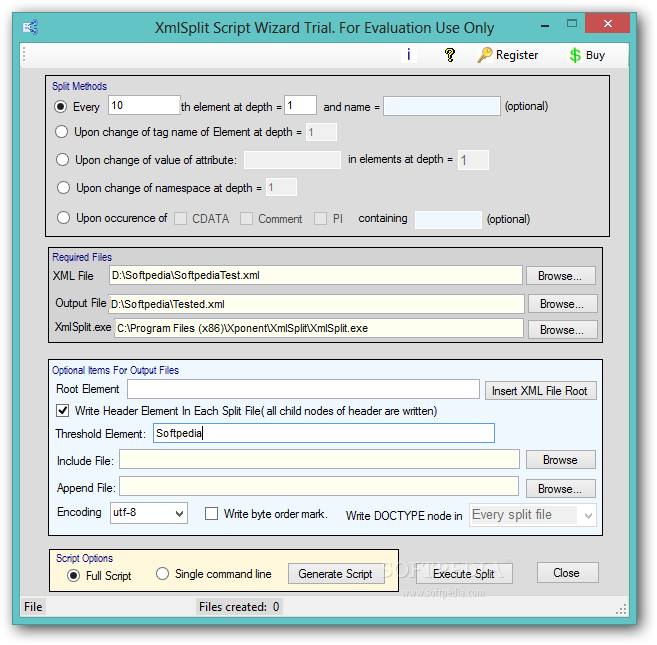
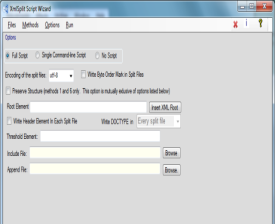
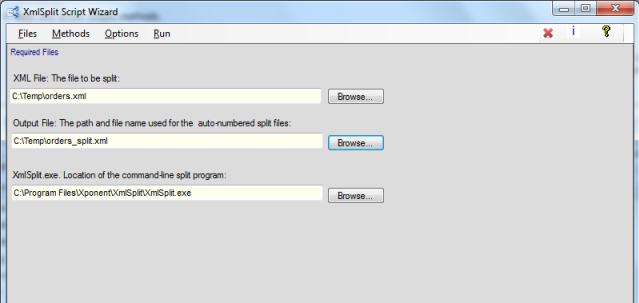
 所以先放出这个工具给大家带来点方便。
所以先放出这个工具给大家带来点方便。 楼主
楼主



 其实这个程序破解起来还是比较容易的,我就是把它的验证给替换了一下而已。
其实这个程序破解起来还是比较容易的,我就是把它的验证给替换了一下而已。


 发表于 2018-5-14 06:21:32
发表于 2018-5-14 06:21:32


