TA的每日心情 | 慵懒
2021-9-1 08:46 |
|---|
签到天数: 61 天 [LV.6]常住居民II
贡士
 
- 积分
- 4080

|
本帖最后由 zhangchaont 于 2021-9-26 13:02 编辑
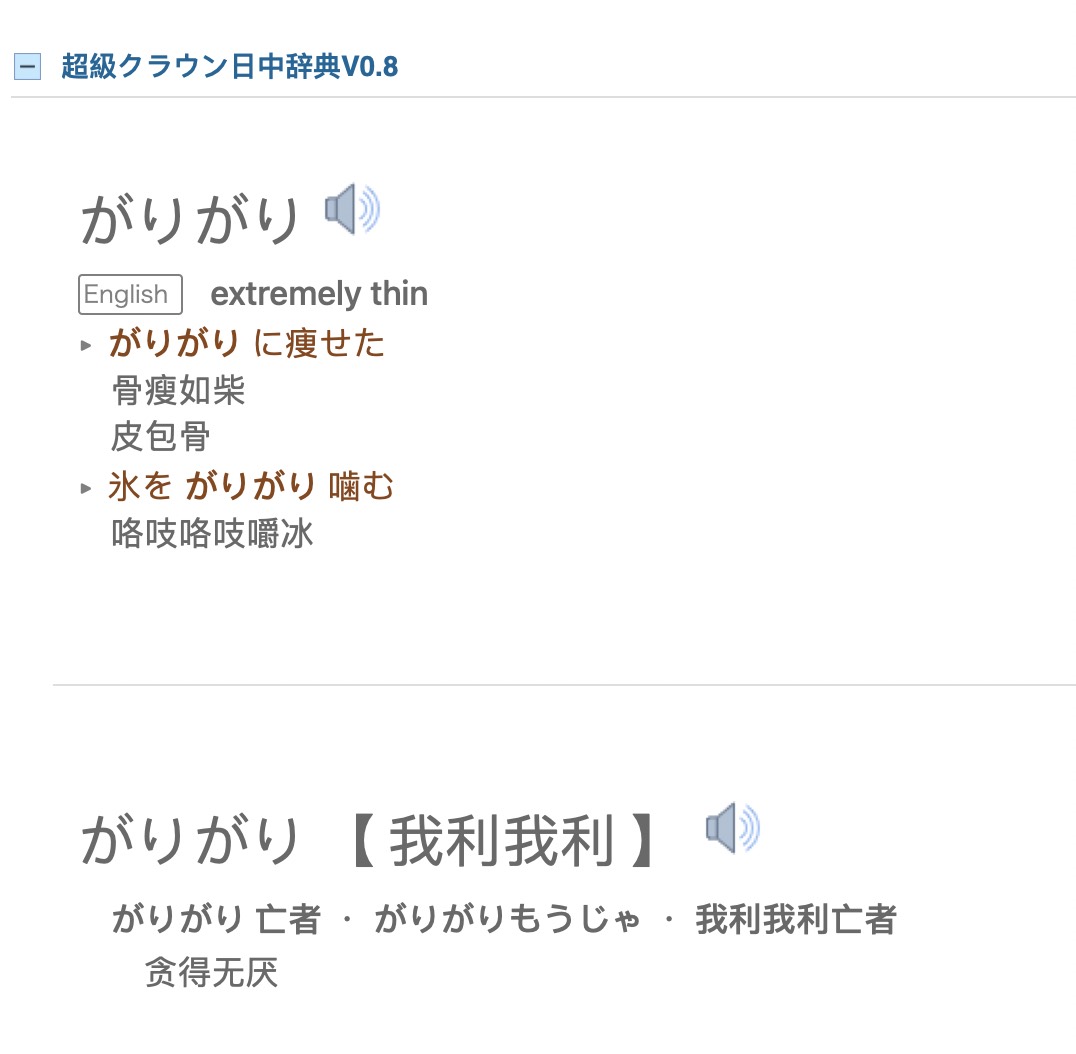
2021年09月26日更新
免责声明:此帖仅为练习mdx/mdd文件的制作,请下载后于24小时内删除。
此次更新做为词典的使用者来讲,变化不大,将之前网友反馈的查询出错的问题修复了。但是从制作上来讲,是完全重新制作的。
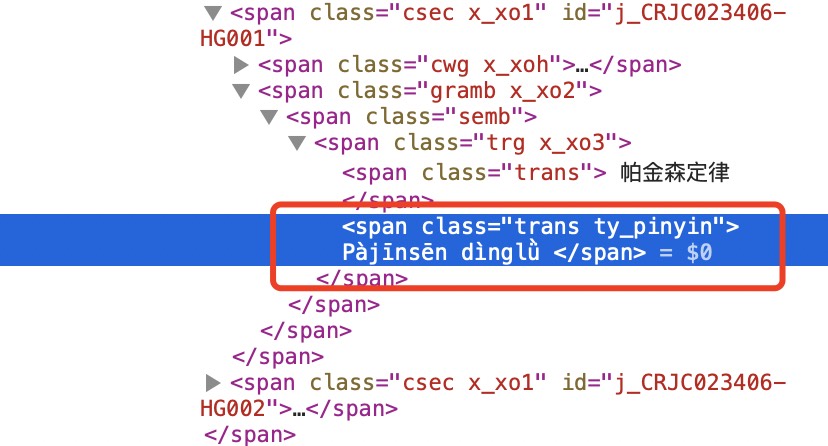
1. 总算找到一个键对应多条内容的方法了。多谢Igmcw兄台的分享。【支持超大文件】Python MDX词典打包工具 2019-11-19更新
在writemdict.py文件中的_build_offset_table函数改成如下:
- def _build_offset_table(self, d):
- # Sets self._offset_table to a table of entries _OffsetTableEntry objects e.
- #
- # where:
- # e.key: encoded version of the key, not null-terminated
- # e.key_null: encoded version of the key, null-terminated
- # e.key_len: the length of the key, in either bytes or 2-byte units, not counting the null character
- # (as required by the MDX format in the keyword index)
- # e.offset: the cumulative sum of len(record_null) for preceding records
- # e.record_null: encoded version of the record, null-terminated
- #
- # Also sets self._total_record_len to the total length of all record fields.
- items = list(d.items())
- items.sort(key=operator.itemgetter(0))
- self._offset_table = []
- offset = 0
- for key, records in items:
- for record in set(records):
- key_enc = key.encode(self._python_encoding)
- key_null = (key + "\0").encode(self._python_encoding)
- key_len = len(key_enc) // self._encoding_length
- # set record_null to a the the value of the record. If it's
- # an MDX file, append an extra null character.
- if self._is_mdd:
- record_null = record
- else:
- record_null = (record + "\0").encode(self._python_encoding)
- self._offset_table.append(_OffsetTableEntry(
- key=key_enc,
- key_null=key_null,
- key_len=key_len,
- record_null=record_null,
- offset=offset))
- offset += len(record_null)
- self._total_record_len = offset
- self._num_entries = len(self._offset_table)
修改是:
- for key, records in items:
- for record in set(records):
和增加了最后一行。
这样就可以支持一个键对多个条目了。所以生成的字典的键值都需要修改成list类型,包括mdd里面的。
2. 把样式单的底色改成白色了,在欧陆里面有底色的话看起来不协调。
附上重写的代码
- from utils import csv_reader
- import os
- from uuid import uuid4
- from bs4 import BeautifulSoup
- from mdict_query.mdict_query import IndexBuilder
- from writemdict.writemdict import MDictWriter
- from jaconv import hira2kata
- from onomatope import isonomatope
- class CrownDict:
- def __init__(self):
- self.csv = csv_reader('src/dictionaries/jpcn.csv')
- self.voice_library = IndexBuilder('src/NHK Accent Library/NHK日本語発音アクセント辞書.mdx')
- self.mdx_dict = {}
- self.mdd_dict = {}
- with open('src/speak.png', 'rb') as f:
- self.mdd_dict['\\speak.png'] = [f.read()]
- def parse(self):
- for row in self.csv:
- key, data = row[0], row[1]
- soup = BeautifulSoup(data, features='html.parser')
- header = soup.find('span', {'class': 'hwg x_xh0'})
- contents = soup.find('span', {'class': 'gramb x_xd0'})
- idiom = soup.find('span', {'class': 'idmb x_xo0'})
- subkeys = self.get_subkeys(header, idiom)
- # add speak icon to header part, and lookup audio for it
- pron_path = uuid4().hex + '.spx'
- spx = self.voice_library_lookup(key)
- if not spx:
- spx = self.voice_library_lookup(subkeys[0])
- if spx:
- self.mdd_dict[f'\\{pron_path}'] = [spx]
- speaker = soup.new_tag('img', src='file:///speak.png')
- audio_link = soup.new_tag('a', href="sound:///" + pron_path)
- header.append(speaker)
- speaker.wrap(audio_link)
- new_soup = BeautifulSoup('', features='html.parser')
- css = new_soup.new_tag('link', href="crown.css")
- jp_section = new_soup.new_tag('div', attrs={'class': 'jp_section'})
- new_soup.extend([css, jp_section])
- jp_section.extend([header, contents])
- if idiom:
- jp_section.append(idiom)
- record = new_soup.prettify()
- # add keys
- if key not in self.mdx_dict:
- self.mdx_dict[key] = [record]
- else:
- self.mdx_dict[key].append(record)
- for subkey in subkeys:
- if subkey != key:
- if subkey not in self.mdx_dict:
- self.mdx_dict[subkey] = [f'@@@LINK={key}']
- else:
- self.mdx_dict[subkey].append(f'@@@LINK={key}')
- @staticmethod
- def get_subkeys(header, idiom):
- subkeys = []
- if '【' in header.text:
- # if has tail then drop it
- # add pronunciation and word keys
- tail = header.find('span', {'class': 'tail'})
- if tail:
- tail.extract()
- header_text = ''.join(header.text.split())
- pron = header_text[:header_text.index('【')]
- word = header_text[header_text.index('【') + 1: -1]
- subkeys.append(pron)
- subkeys.append(word)
- if isonomatope(word):
- subkeys.append(hira2kata(word))
- else:
- pron = ''.join(header.text.split())
- subkeys.append(pron)
- # add onomatope keys
- if isonomatope(pron):
- subkeys.append(hira2kata(pron))
- # add idiom keys
- if idiom:
- for idm_sec in idiom.find_all('span', {'class': 'idmsec x_xo1'}):
- idm_tags = idm_sec.find_all('span', {'class': 'idm'})
- idm_texts = [''.join(idm.text.split()) for idm in idm_tags]
- idm_texts = list(set(idm_texts))
- subkeys.extend(idm_texts)
- return subkeys
- def voice_library_lookup(self, key):
- result = self.voice_library.mdx_lookup(key)
- if result:
- soup = BeautifulSoup(result[0], features='html.parser')
- href = soup.a.get('href')
- if 'entry' in href:
- soup = BeautifulSoup(self.voice_library.mdx_lookup(href[8:])[0], features='html.parser')
- link = soup.a['href'][9:].replace('/', '\\')
- spx = self.voice_library.mdd_lookup(link)
- if spx:
- spx = spx[0]
- return spx
- def write(self):
- description = """クラウン日中辞典 / Sanseido's Crown Japanese-Chinese Dictionary
- Copyright © 2010, 2019 Sanseido Company Ltd., under licence to Oxford University Press. All rights reserved."""
- dict_name = "超級クラウン日中辞典V0.8"
- mdx_writer = MDictWriter(self.mdx_dict, dict_name, description=description)
- with open(os.path.expanduser('~/Downloads/クラウン日中辞典/crown.mdx'), 'wb') as outfile:
- print("Writing mdx starts...")
- mdx_writer.write(outfile)
- print("Writing finished.")
- mdd_writer = MDictWriter(self.mdd_dict, dict_name, description=description, is_mdd=True)
- with open(os.path.expanduser('~/Downloads/クラウン日中辞典/crown.mdd'), 'wb') as outfile:
- print("Writing mdd starts...")
- mdd_writer.write(outfile)
- print("Writing finished.")
- if __name__ == '__main__':
- crown = CrownDict()
- crown.parse()
- crown.write()
2021年09月23日更新
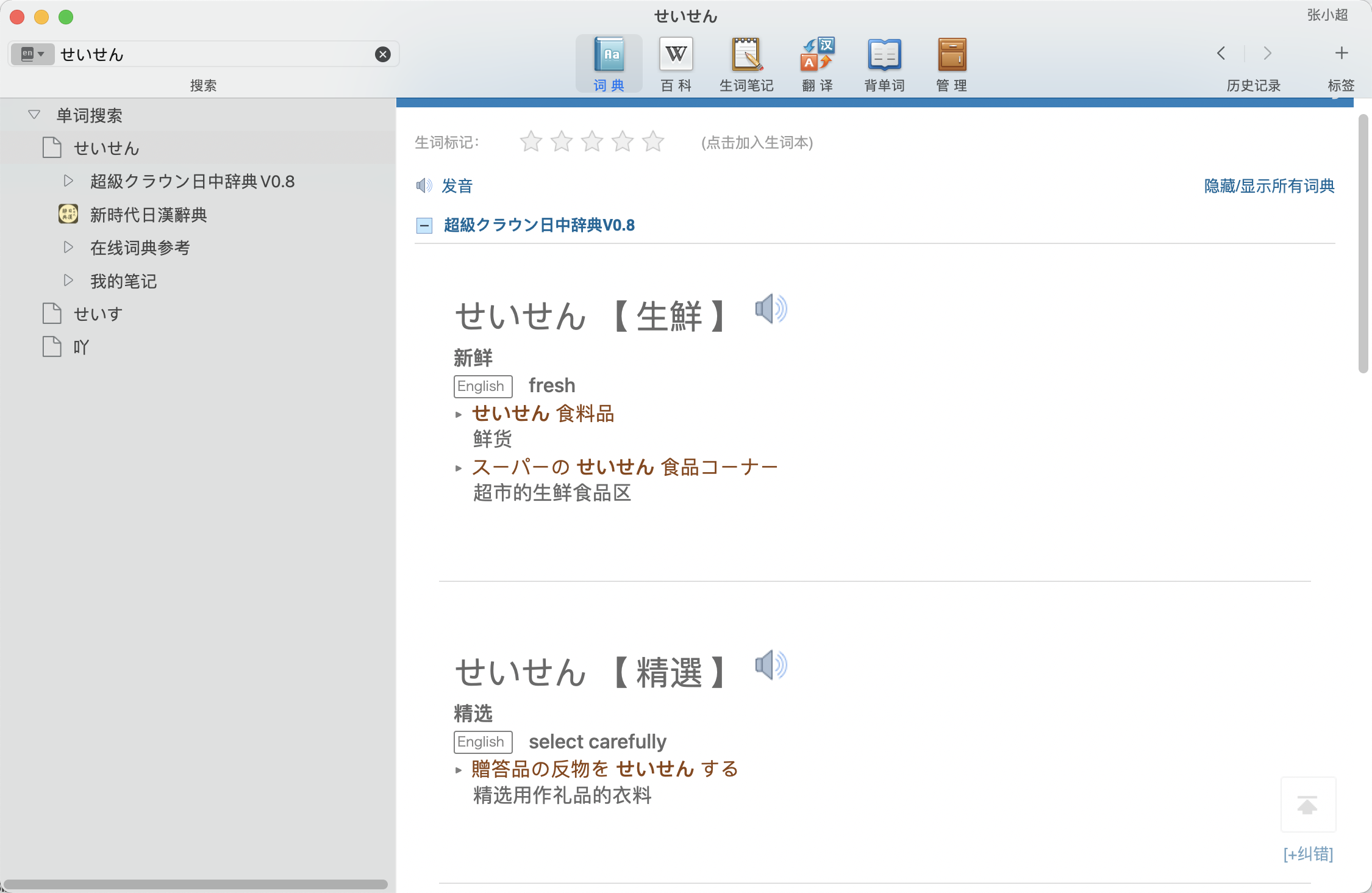
将NHK日本語発音アクセント辞書中的发音添加到词典中了,不全,所以有些单词是没有发音的。不过,基本上没有发音的单词也不常用,一般使用的话问题不大。另外,每个单词我就只配了一个发音,以后看情况再说吧。
2021年09月18日更新
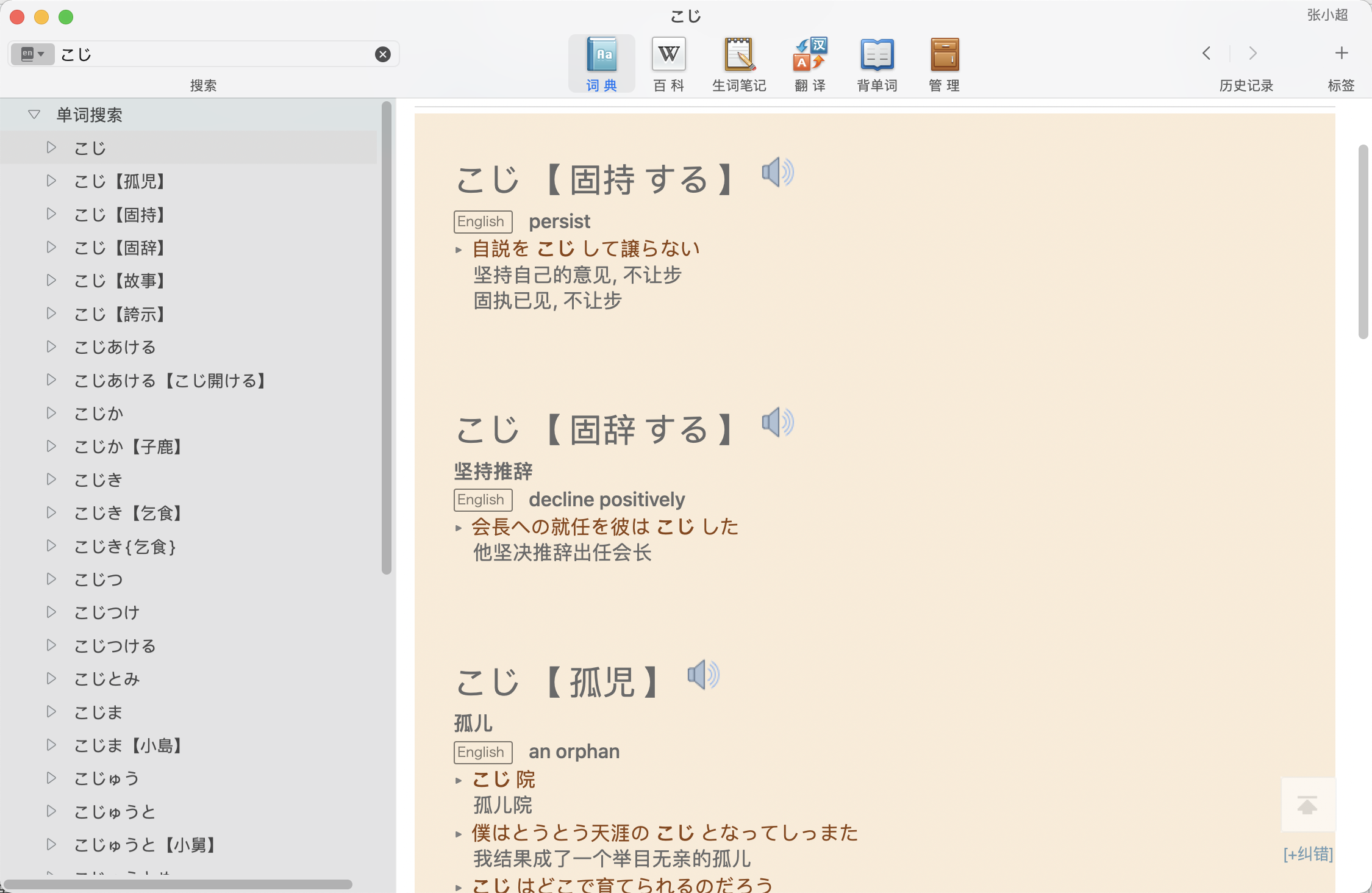
1. 修改了一个小问题,きっと这个词条有两个,对应不同的意思,用单词加读音拼在一起不能解决键冲突的问题,已经修复;
2. 为拟声拟态词增加了片假名的查询,在小说中,为了强调,很多拟声拟态词都会写成片假名的形式,这次增加了这个功能。这个是用的这个网页上的列表稍加处理实现的,虽然不是很全,但是常用的应该都有了。
代码就不贴出来了,之前的代码如果能够看懂的话,这些小修改应该都能明白的。
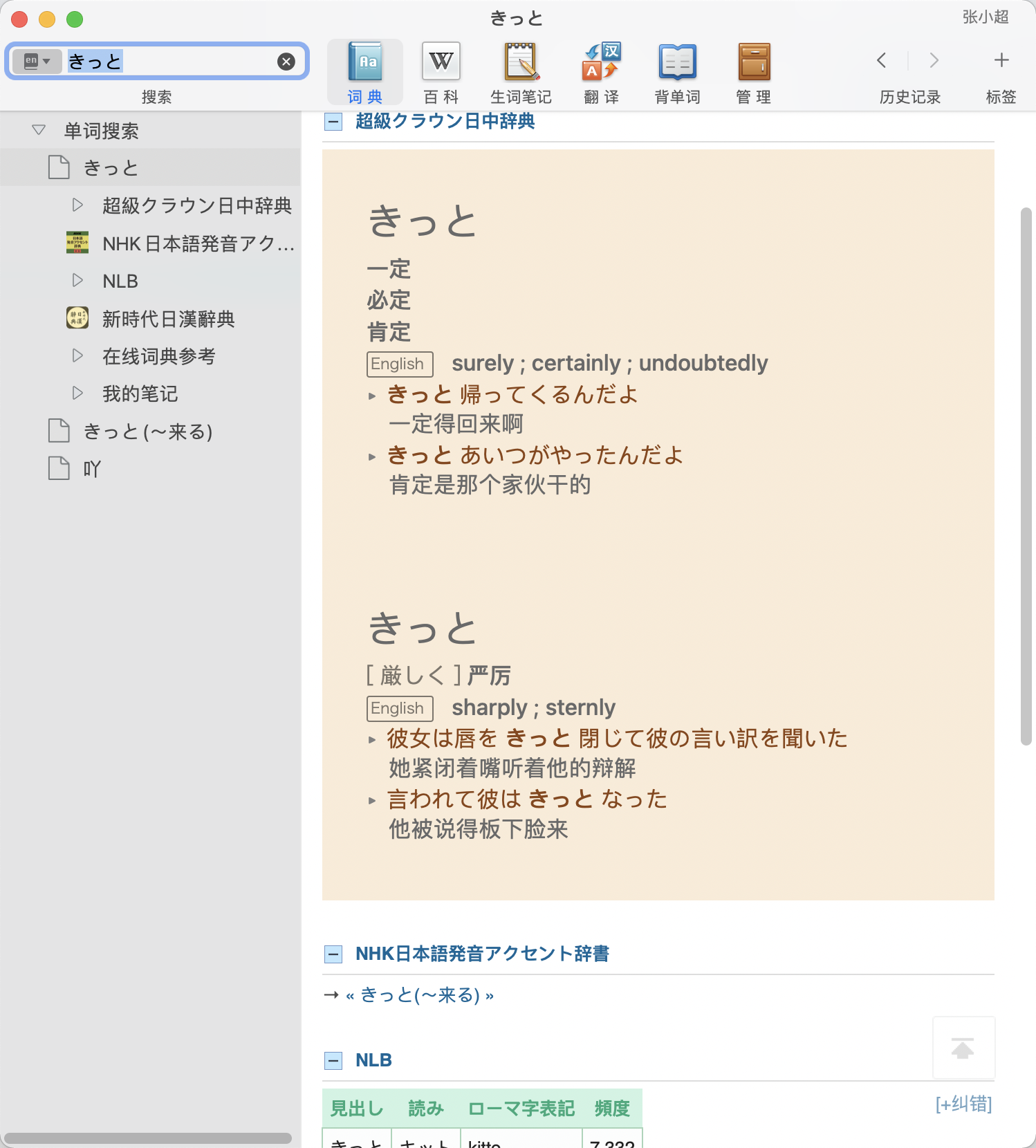
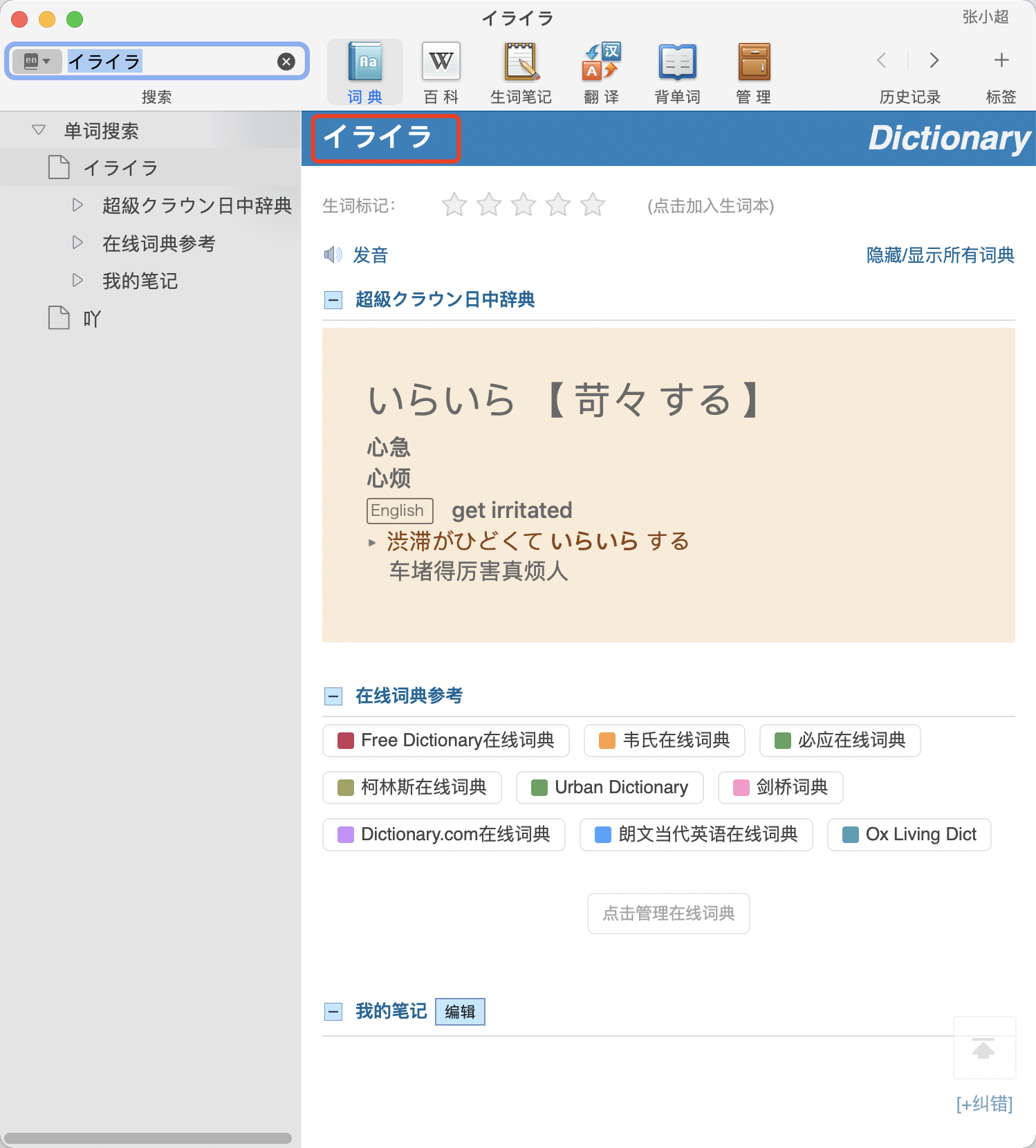

2021年09月15日更新
此次更新实现了用假名查询。
同音、同形的词条会汇总显示到一个页面里。

另外也可以单独查询固定搭配。

实现的思路如下:
第一步,把单词和读音并在一起做为词条,这样就解决了键的冲突问题;
第二步,添加单词查询键,如果没有重复的就用@@@LINK=key来跳转,有冲突键就把内容拼接到一起;
第三步,添加读音查询键,思路同第二步;
第四步,添加固定搭配查询键,如果有冲突键就把固定搭配单独抽取出来和冲突键的内容拼接到一起;不冲突的话单独显示固定搭配的释义;
如果有什么bug的话欢迎反馈,以后后续继续优化。
代码如下:
- import csv
- import os
- import sys
- from bs4 import BeautifulSoup
- from writemdict.writemdict import MDictWriter
- import re
- def dictionary_data():
- csv.field_size_limit(sys.maxsize)
- d = {}
- with open('jpcn.csv', 'r') as csvfile:
- reader = csv.reader(csvfile)
- for row in reader:
- html = '''<html>
- <head>
- <link rel="stylesheet" href="jpdict.css" type="text/css">
- </head>
- <body>
- <div class="jp_section">
- </div>
- </body>
- </html>'''
- # Combine entry and pronunciation as key to avoid key conflict
- soup = BeautifulSoup(html, features='html.parser')
- def_soup = BeautifulSoup(row[1], features='html.parser')
- header = def_soup.find('span', {'class': 'hwg x_xh0'})
- key = ''.join(header.text.split())
- definition = def_soup.find('span', {'class': 'gramb x_xd0'})
- idiom = def_soup.find('span', {'class': 'idmb x_xo0'})
- soup.div.insert(0, header)
- soup.div.insert(1, definition)
- if idiom:
- soup.div.insert(2, idiom)
- d[key] = soup.prettify()
- jp_section = soup.find('div', {'class': 'jp_section'})
- # Add Japanese word entry to dictionary, if key conflicts put the latter with previous entry together
- word = row[0].strip()
- if word not in d:
- d[word] = f'@@@LINK={key}'
- else:
- if word != key:
- definition_of_heteronym = d[word]
- if "@@@LINK" in definition_of_heteronym:
- conflict_key = definition_of_heteronym[8:]
- definition_of_heteronym = d[conflict_key]
- soup_of_heteronym = BeautifulSoup(definition_of_heteronym, features='html.parser')
- soup_of_heteronym.body.append(jp_section)
- d[word] = soup_of_heteronym.prettify()
- # Add pronunciation entries, if key conflicts put it to the end
- if '【' in key:
- pron = re.search('(^.+?)【', key).group(1)
- if pron not in d:
- d[pron] = f"@@@LINK={key}"
- else:
- definition_of_homophone = d[pron]
- if "@@@LINK" in definition_of_homophone:
- conflict_key = d[pron][8:]
- definition_of_homophone = d[conflict_key]
- soup_of_homophone = BeautifulSoup(definition_of_homophone, features='html.parser')
- soup_of_homophone.body.append(jp_section)
- d[pron] = soup_of_homophone.prettify()
- # Add idiom entries, if key conflicts put it to the end
- if idiom:
- for idm_sec in idiom.find_all('span', {'class': 'idmsec x_xo1'}):
- idm_tags = idm_sec.find_all('span', {'class': 'idm'})
- idm_texts = [''.join(idm.text.split()) for idm in idm_tags]
- idm_texts = list(set(idm_texts))
- for n, idm in enumerate(idm_texts):
- html_frame_soup = BeautifulSoup(html, features='html.parser')
- new_jp_section = html_frame_soup.find('div', {'class': 'jp_section'})
- new_jp_section.append(idm_sec)
- if n == 0:
- if idm not in d:
- d[idm] = html_frame_soup.prettify()
- else:
- conflict_key_definition = d[idm]
- if '@@@LINK' in conflict_key_definition:
- conflict_key = conflict_key_definition[8:]
- conflict_key_definition = d[conflict_key]
- soup_of_conflict = BeautifulSoup(conflict_key_definition, features='html.parser')
- soup_of_conflict.body.append(new_jp_section)
- d[conflict_key] = soup_of_conflict.prettify()
- else:
- d[idm] = f'@@@LINK={idm_texts[0]}'
- if reader.line_num % 1000 == 0:
- print(reader.line_num)
- return d
- def write_dict(d):
- description = """クラウン日中辞典 / Sanseido's Crown Japanese-Chinese Dictionary
- Copyright © 2010, 2019 Sanseido Company Ltd., under licence to Oxford University Press. All rights reserved."""
- writer = MDictWriter(d, "超級クラウン日中辞典 ", description=description)
- with open(os.path.expanduser('~/Downloads/クラウン日中辞典/jpdict.mdx'), 'wb') as outfile:
- print("Writing mdx starts...")
- writer.write(outfile)
- print("Writing finished.")
- if __name__ == '__main__':
- dictionary = dictionary_data()
- write_dict(dictionary)
2021年09月10日更新
之前的提供下载的词典有点问题,固定搭配部分没有提取出来,现在加进去了,前面下载过的朋友请重新下载一下。
目前发现的问题:
1. 比如いらいら这个词,平时一般不会用苛々这个写法,但是在词典里面不按这个来查就检索不出来;这个我觉得可以用@@@LINK来解决
2. 気有き、け两个读音,是分成两个词条的,目前的做法只会保留一个词条,这个我还没有想到什么解决办法,下周再说。
日语的词典比较少,以前做Anki卡片的时候是从沪江上扒取的,不过沪江小D上的解释有些是有问题的,还有一个是因为我经常扒取,把我的IP给封了,不过macOS自带的词典APP里面是提供的了三个日语词典的,一个中日日中词典就是标题中的这个,还有一个日英词典,和大辞林。我最近一直想着要把这个自带的词典转成mdx,这样就可以轻易的制成Anki卡片了。经过这两天的折腾,成品出炉了。

手机上的效果:
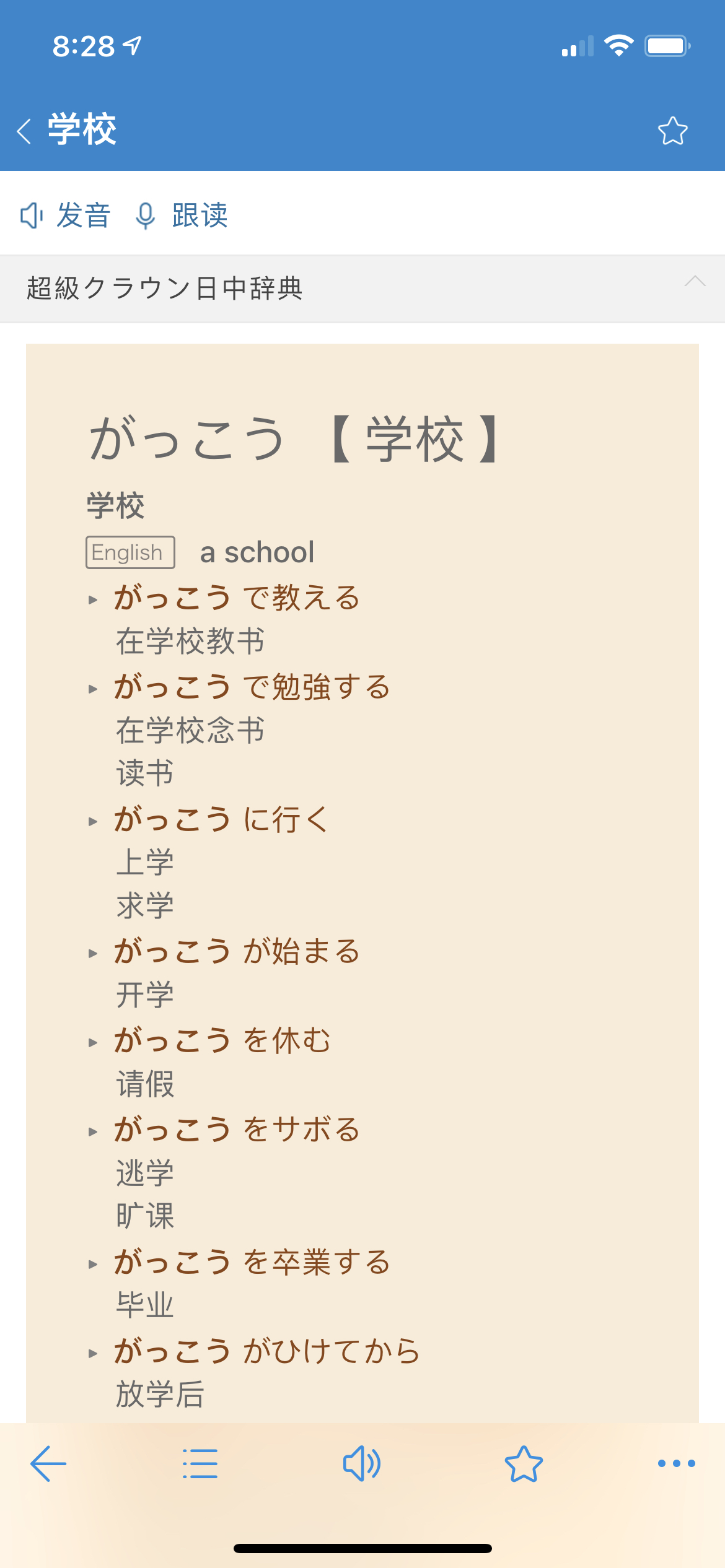
用在Anki上的效果:

有需要的朋友请拿去吧。
下载链接上面
下面分享一下制作过程,以便其他有需要的朋友能够将其他小语种的macOS自带词典转成mdx。
1. 首先安装pyglossary:
- brew install python3 pygobject3 gtk+3
- pip3 install pyglossary
成功安装后就可以在终端运行:
界面如下:
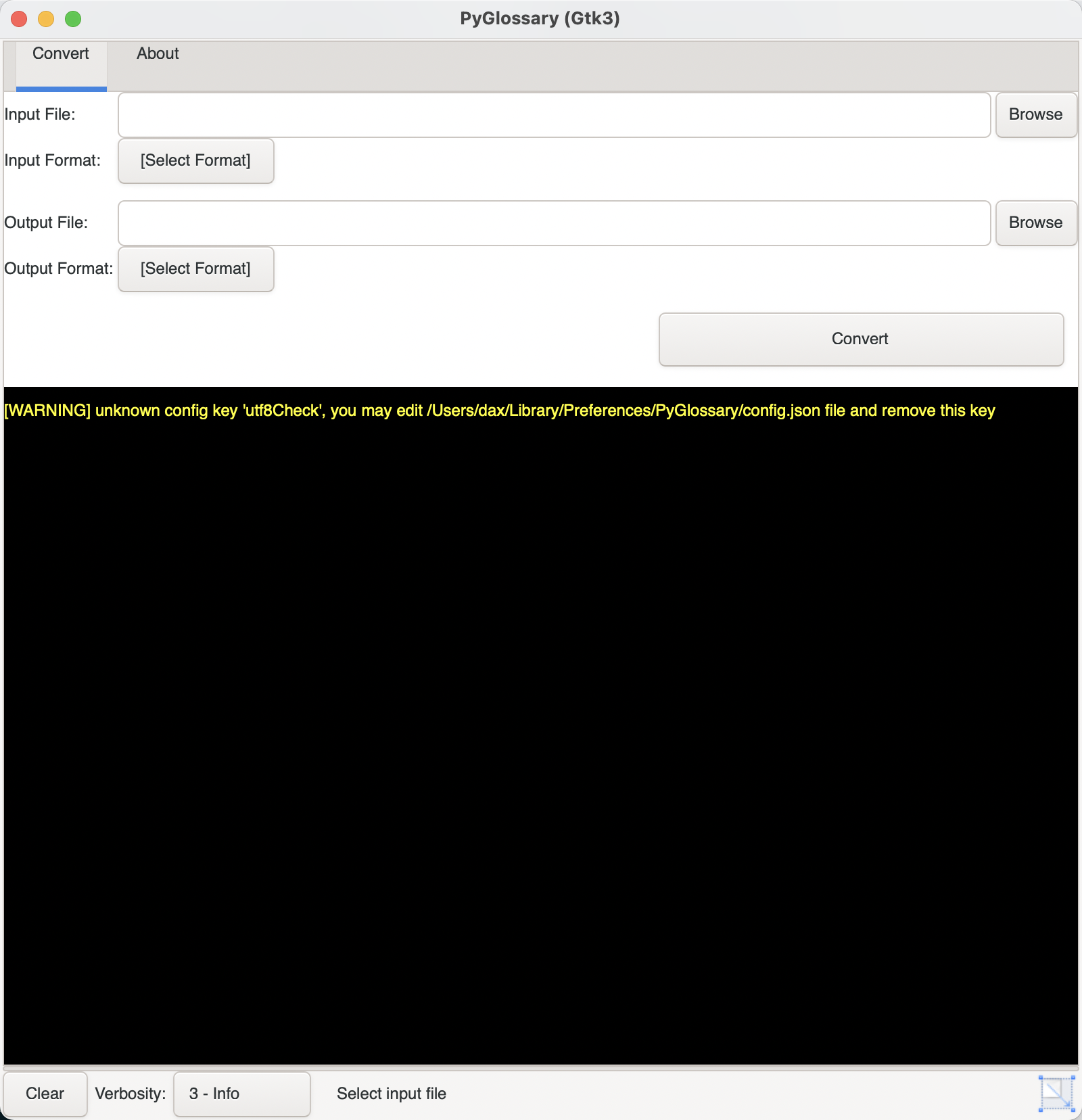
2. 下一步就是需要找到自带辞典的位置了。
- /System/Library/AssetsV2/com_apple_MobileAsset_DictionaryServices_dictionaryOSX/
打开文件夹可以看到一堆看不懂的文件夹名字。
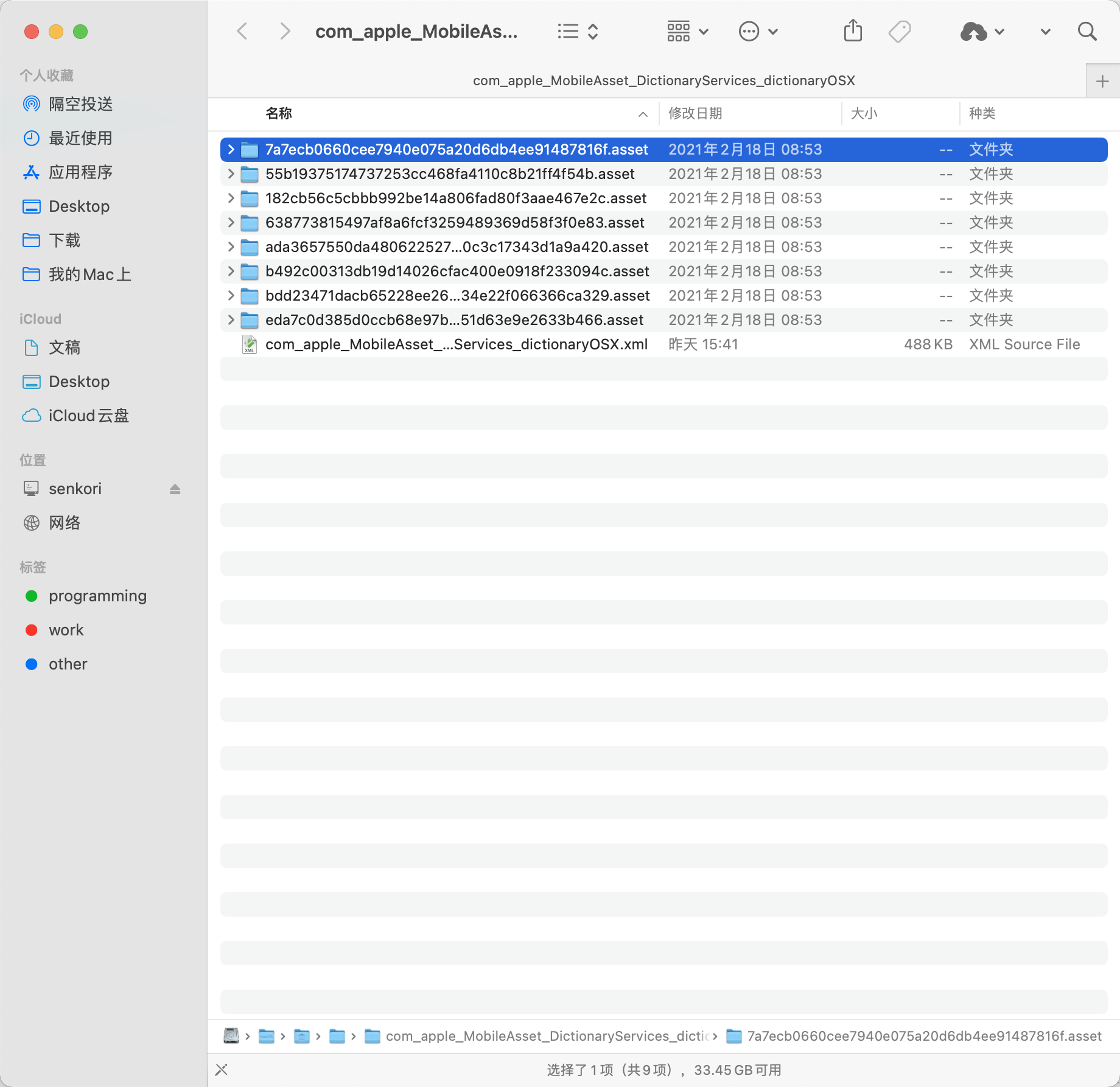
一个个点开,找到你需要的字典,在contents文件夹里面有一个Body.data,这个就是词典的数据文件,另外还有一个DefaultStyle.css,这个是样式单,后面也会用到。
3. 然后就是转换了,自己选择一种格式,我选择是csv,这个编辑起来比较方便。转换成CSV的文件后(好大一个),首先可以用Vim或者其他编辑器预处理一下。
4. 预处理,我删除了一些链接,因为没有什么用,还有中文部分(中文词条用日语解释)也删除了,这个用不到。
5. 用其中一个词条测试了一下效果,发现居然里面有很多重复的内容,可能是为不同的系统准备的,但是我只要一个词头和解释部分就够了,这部分在Python里面用BeautifulSoup搞定。
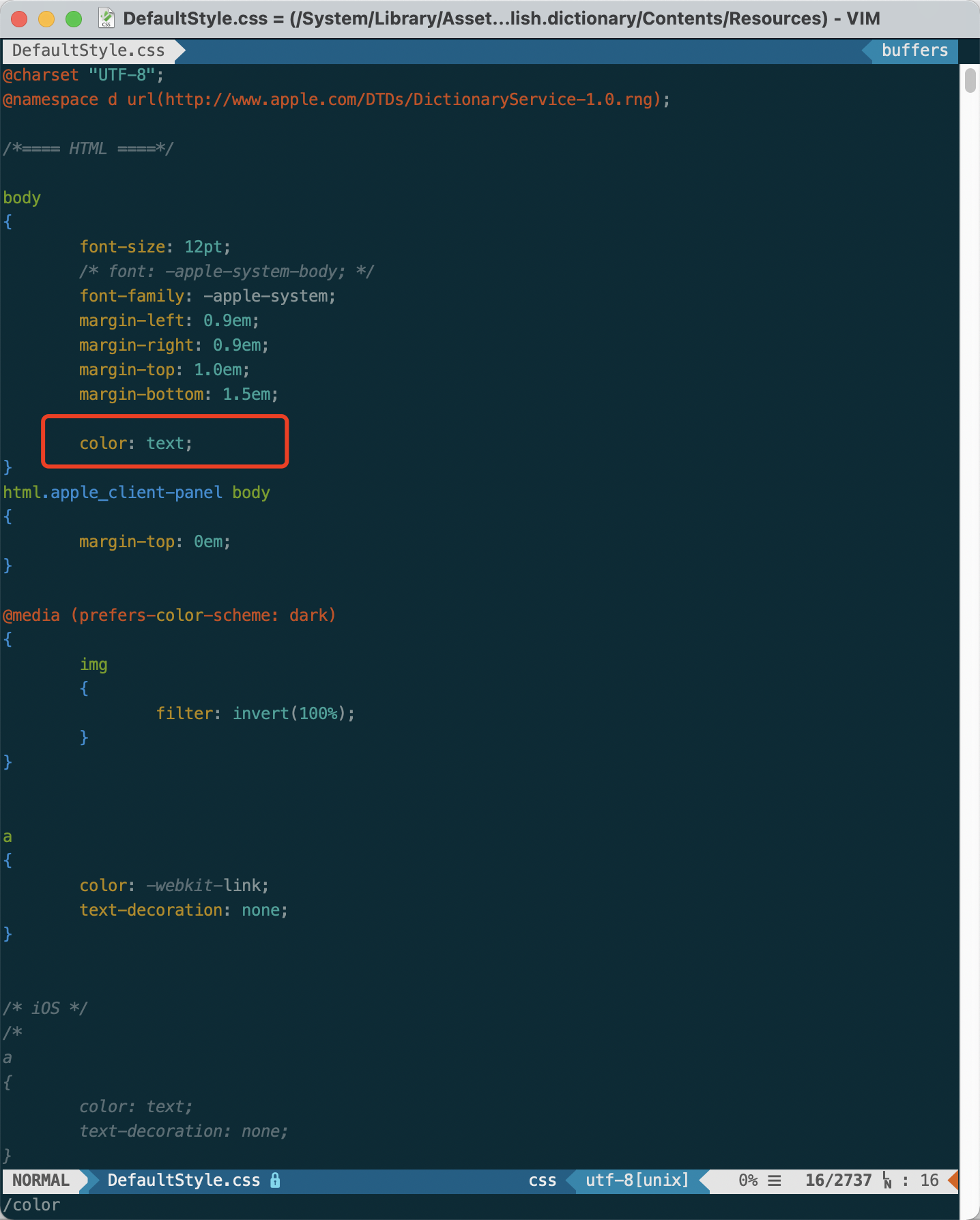
6. 定制CSS,本来我想自己写一个的,后来发现也比较麻烦,毕竟自己对这些只会点皮毛,还是在原来的上面改。但是这个自带的CSS设计的也挺复杂,不过我只需要改配色,就只要搜索color就可以了,然后改个颜色试试看效果就可以了,如下图:
7. 好了,把这些准备好了以后可以准备用writemdict库来编译成mdx文件了。
在PyCharm的终端里面,- git clone https://github.com/zhansliu/writemdict
a. 在writemdict文件夹里面新建一个__init__.py文件;
b. writemdict.py文件中import部分有三个需要改成- from .ripemd128 import ripemd128
- from html import escape
- from .pureSalsa20 import Salsa20
两个前面加个点,还有一个要改成html才行。
8. 写代码完成制作。我所用的代码如下,供参考:
- import csv
- import os
- import sys
- from bs4 import BeautifulSoup
- from writemdict.writemdict import MDictWriter
- def dictionary_data():
- csv.field_size_limit(sys.maxsize) #设置csv的长度,要不然会报错。
- d = {} #建一个词典变量,用来存储后面解析出来的词条和释义。
- with open(os.path.expanduser('~/Downloads/jpdict/jpcn.csv'), 'r') as csvfile:
- reader = csv.reader(csvfile)
- for row in reader:
- if reader.line_num > 3: #最开始的几行不是词条,其实可以在Vim里面预处理掉
- word = row[0] #每一行第一个是词条,第二个是释义;
- html = '''<html>
- <head>
- <link rel="stylesheet" href="jpdict.css" type="text/css">
- </head>
- <body>
- <div class="jp_section">
- </div>
- </body>
- </html>''' #新建一个html框架,div部分用来插入后面要插入的单词和释义
- new_soup = BeautifulSoup(html, features='html.parser')
- soup = BeautifulSoup(row[1], features='html.parser') # 把释义部分用BeautifulSoup来分析
- header = soup.find('span', {'class': 'hwg x_xh0'}) # 找到词头部分
- definition = soup.find('span', {'class': 'gramb x_xd0'}) # 找到释义部分
- idiom = soup.find('span', {'class': 'idmb x_xo0'}) # 找到固定搭配部分
- new_soup.div.insert(0, header) # 将词头部分插入到html框架的jp_section部分
- new_soup.div.insert(1, definition) # 将释义部分插入到html框架的jp_section部分
- if idiom:
- new_soup.div.insert(2, idiom) #将固定搭配插入到html框架的jp_section部分
- d[word] = new_soup.prettify() # 把词条和抽取的释义添加词典里面
- if reader.line_num % 1000 == 0:
- print(reader.line_num)
- return d
- def write_dict(dictionary):
- #这一步就只需要按照writemdict库里面的说明操作即可
- description = """クラウン日中辞典 / Sanseido's Crown Japanese-Chinese Dictionary
- Copyright © 2010, 2019 Sanseido Company Ltd., under licence to Oxford University Press. All rights reserved."""
- writer = MDictWriter(dictionary, "超級クラウン日中辞典 ", description=description)
- with open(os.path.expanduser('~/Downloads/jpdict/jpdict.mdx'), 'wb') as outfile:
- print("Writing mdx starts...")
- writer.write(outfile)
- print("Writing finished.")
- if __name__ == '__main__':
- dictionary = dictionary_data()
- write_dict(dictionary)
完工!!!!!
后面空了把另外两个日语词典也做一下:)
以上这些操作只是提供一些操作方面的思路,需要有一定的电脑知识为基础,实际的过程中可能出现各种各样的问题,请自行搜索解决。
我把调整过的CSS替换掉原来系统自带的,自带的词典APP也显示成我想要的样子了。
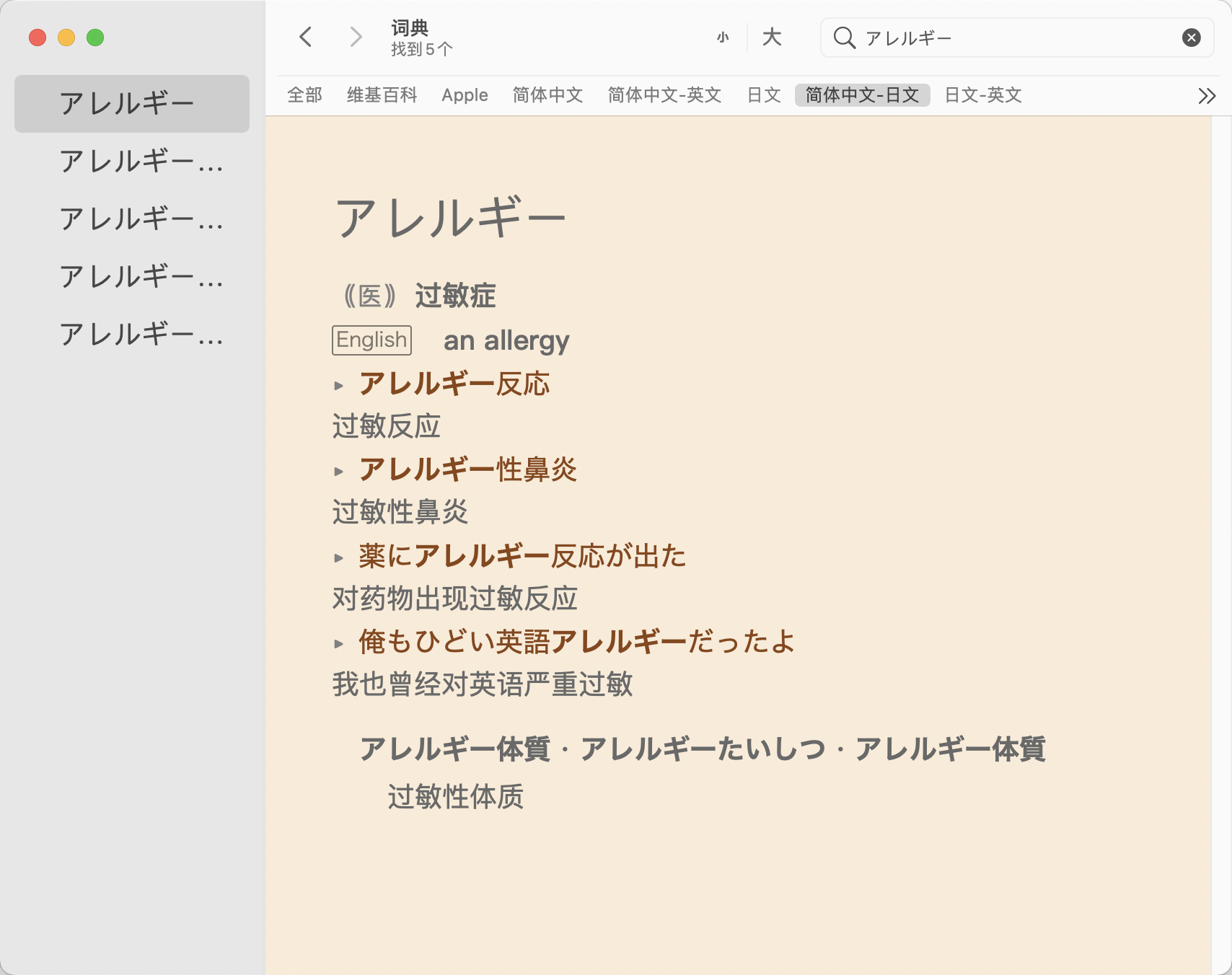
|
评分
-
7
查看全部评分
-
|



 [复制链接]
[复制链接]


 发表于 2021-9-9 16:16:06
发表于 2021-9-9 16:16:06

 楼主
楼主